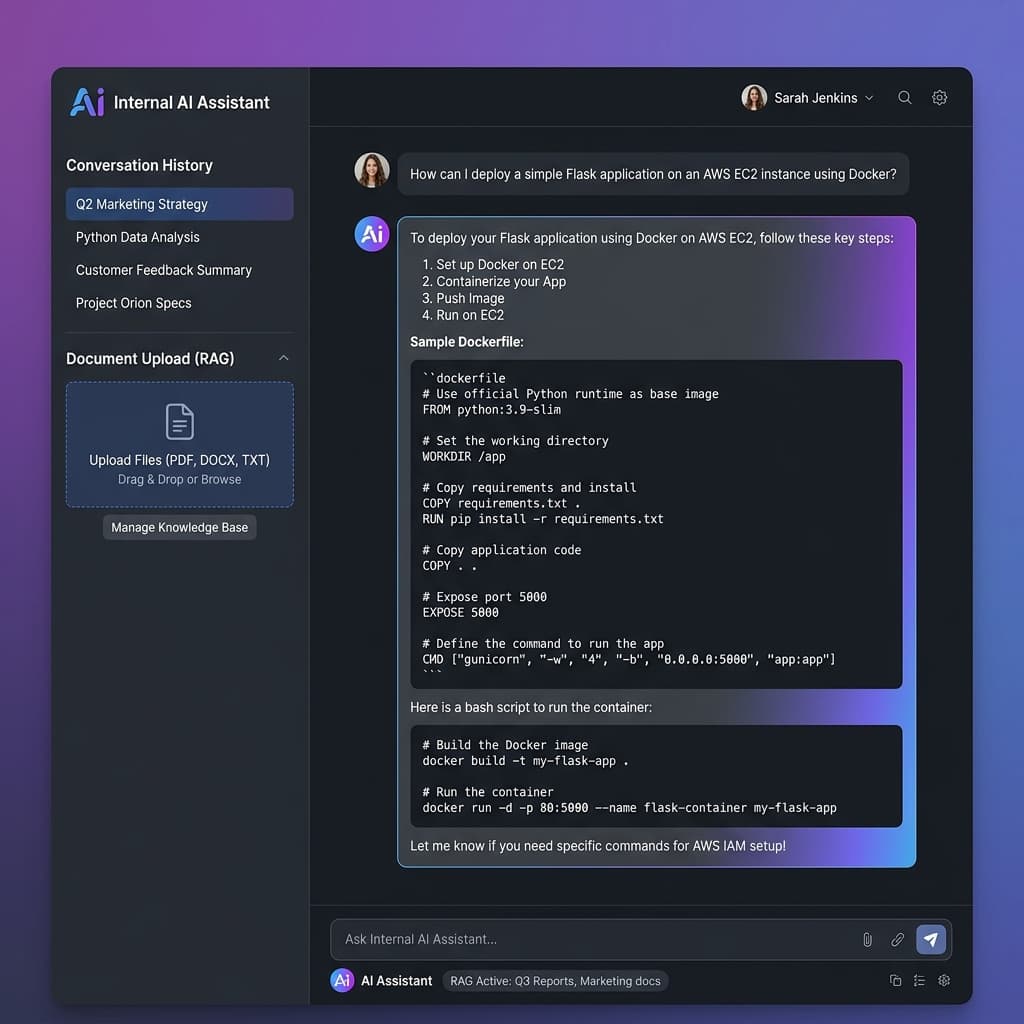
Internal AI Assistant (RAG)
A complete Internal AI Assistant built end-to-end using n8n workflows and Retrieval-Augmented Generation (RAG) architecture. Uses pgvector for vector similarity search and Ollama for running a local Large Language Model, ensuring data privacy.
My Role
AI Developer — Architecture, Vector DB, LLM Integration, Full Stack
Tech Stack
n8nPythonpgvectorOllamaLLMPostgreSQLRAG
Source Code
github.com/wongsakronKey Highlights
- Full RAG pipeline automated with n8n: document ingestion → embedding → retrieval → generation
- pgvector for high-performance vector similarity search
- Local LLM deployment with Ollama (no cloud dependency)
- Complete data privacy — all processing happens on-premises